2nd 3D Face Alignment in the Wild Challenge
- Dense Reconstruction from Video -
In conjunction with ICCV 2019, Seoul, Korea
Oct 27th- Nov 2nd, 2019
Program
Date: Saturday, November 2nd
Location: 317A
| 8:50-9:00 | Welcome and opening |
|---|---|
| 9:00-10:00 |
Invited Talk: Photorealistic Codec Avatar
Shugao Ma (Facebook Reality Labs) |
| 10:00-10:20 | 3DFAW Challenge Overview |
| 10:20-10:40 |
Multi-view 3d face reconstruction in the wild using siamese networks
Eduard Ramon Maldonado, Janna Escur, Xavier Giro-i-Nieto |
| 10:40-11:00 |
3D Face Shape Regression From 2D Videos with Multi-reconstruction and Mesh Retrieval
Xiao-Hu Shao, Jiangjing Lyu, Junliang Xing, Lijun Zhang, Xiaobo Li, Xiang-Dong Zhou, Yu Shi |
| 11:00-11:20 |
Face Alignment meets 3D Reconstruction
Yinglin Zheng, Ming Zeng, Xuan Cheng, Hui Li |
| 11:20-11:30 | Closing remarks |
Keynote Speaker

Description
Face alignment - the problem of automatically locating detailed facial landmarks across different subjects, illuminations, and viewpoints - is critical to face analysis applications, such as identification, facial expression analysis, robot-human interaction, affective computing, and multimedia.
3D face alignment approaches have strong advantages over 2D with respect to representational power and robustness to illumination and pose. 3D approaches accommodate a wide range of views. Depending on the 3D model, they easily can accommodate a full range of head rotation. Disadvantages are the need for 3D images and controlled illumination, as well as the need for special sensors or synchronized cameras in data acquisition.
Because these requirements often are difficult to meet, 3D alignment from 2D video or images has been proposed as a potential solution. Over the past few years a number of research groups have made rapid advances in dense 3D alignment from 2D video and obtained impressive results. How these various methods compare is relatively unknown. Previous benchmarks addressed sparse 3D alignment and single image 3D reconstruction. No commonly accepted evaluation protocol exists for dense 3D face reconstruction from video with which to compare them.
To enable comparisons among alternative methods, we present the 2nd 3D Face Alignment in the Wild - Dense Reconstruction from Video Challenge. This topic is germane to both computer vision and multimedia communities. For computer vision, it is an exciting approach to longstanding limitations of single-image 3D reconstruction approaches. For multimedia, 3D alignment would enable more powerful applications.
Main track
3DFAW is intended to bring together computer vision and multimedia researchers whose work is related to 2D or 3D face alignment. We are soliciting original contributions which address a wide range of theoretical and application issues of 3D face alignment for computer vision applications and multimedia including, including but not limited to:
- 3D and 2D face alignment from 2D dimensional images
- Model- and stereo-based 3D face reconstruction
- Dense and sparse face tracking from 2D and 3D dimensional inputs
- Applications of face alignment
- Face alignment for embedded and mobile devices
- Facial expression retargeting (avatar animation)
- Face alignment-based user interfaces
Challenge track
The 2nd 3DFAW Challenge evaluates 3D face reconstruction methods on a new large corpora of profile-to-profile face videos annotated with corresponding high-resolution 3D ground truth meshes. The corpora includes profile-to-profile videos obtained under a range of conditions:
- high-definition in-the-lab video,
- unconstrained video from an iPhone device
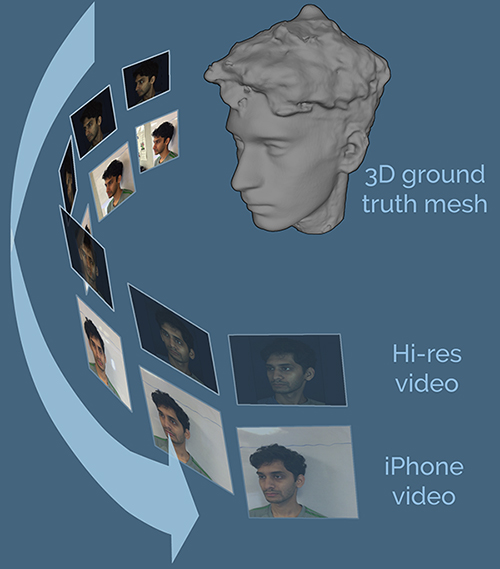
Figure 1. Ground truth mesh and profile-to-profile video of a subject.
For each subject, high-resolution 3D ground truth scans were obtained using a Di4D imaging system. The goal of the challenge is to reconstruct the 3D structure of the face from the two different video sources.
If you are interested in downloading the 3DFAW-Video dataset please download and sign the EULA and email the scanned copy back to lijun(at)cs(dot)binghamton(dot)edu.
Evaluation and Submissions
Please visit the Codalab page where the competition is hosted. Additionally, the evaluation code can be downloaded here for local use by participants. The requirements file for the local environment setup can be downloaded from the same repository. Please report any bugs in the evaluation code in the issues of the repository.
Please note that along with your submission to Codalab competition page, in order to be included in the leaderboard, you are required to submit a short paper containing the description of your method. For paper submission to the workshop, visit our CMT page. When submitting your paper to CMT, please also email rohithkp(at)andrew(dot)cmu(dot)edu with your username/Team name on Codalab, and your workshop paper title, to make it easier to link your paper to the Codalab submissions.
Challenge paper submissions must be written in English and must be sent in PDF format. Each submitted paper must be no longer than four (4) pages, excluding references. Please refer to the ICCV submission guidelines for instructions regarding formatting, templates, and policies. The submissions will be reviewed by the program committee and selected papers will be published in ICCV Workshop proceedings, IEEE Xplore & CVF Open Access.
Dates
Please note that the challenge end date has been extended till the 20th of August, and submissions can be made on the Codalab competition till the 20th. Also, please note the extended workshop paper submission deadlines.
Challenge Track
- June 27th: Challenge site opens, training data available
- August 1st: Testing phase begins
- August 20th: Competition ends - Extended Date (challenge paper submission - optional)
Workshop Track
- August 31st: Paper submission deadline
- September 11th: Notification of acceptance
- September 18th: Camera ready submission
Workshop chairs
- Laszlo A. Jeni, Carnegie Mellon University, USA
- Jeffrey F. Cohn, University of Pittsburgh, USA
- Lijun Yin, Binghamton University, USA
Data chairs
- Rohith Krishnan Pillai, Carnegie Mellon University, USA
- Huiyuan Yang, Binghamton University, USA
- Zheng Zhang, Binghamton University, USA
Technical program committee
- Abhinav Dhall, Australian National University, Australia
- Gábor Szirtes, KÜRT Akadémia / bsi.ai
- Hamdi Dibeklioglu, Bilkent University, Turkey
- Michel Valstar, University of Nottingham, UK
- Patrik Huber, University of Surrey, UK
- Sergio Escalera, University of Barcelona, Spain
- Shaun Canavan, University of South Florida, USA
- Vitomir Štruc, University of Ljubljana, Slovenia
- Xiaoming Liu, Michigan State University, USA
- Xing Zhang, A9
- Zoltan Kato, University of Szeged, Hungary